Strategies to store uncertain data in a database
CORE Admin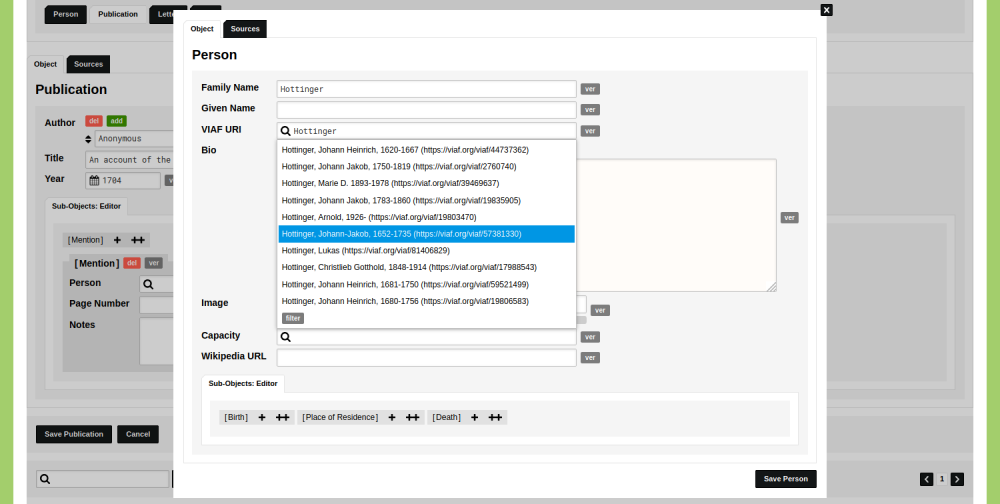
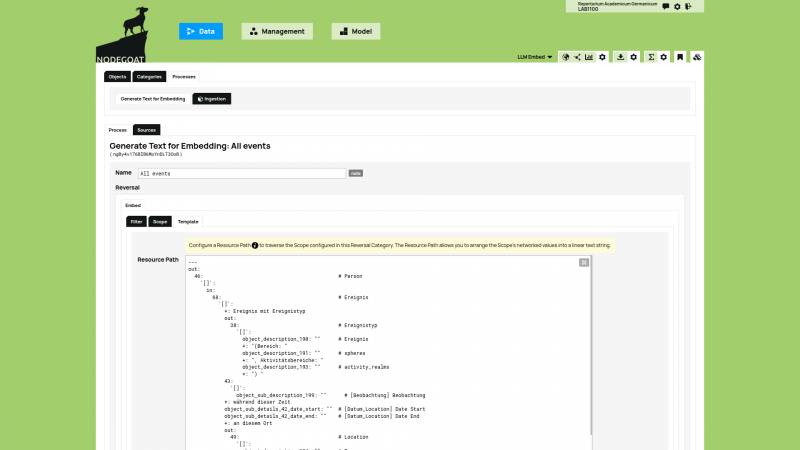
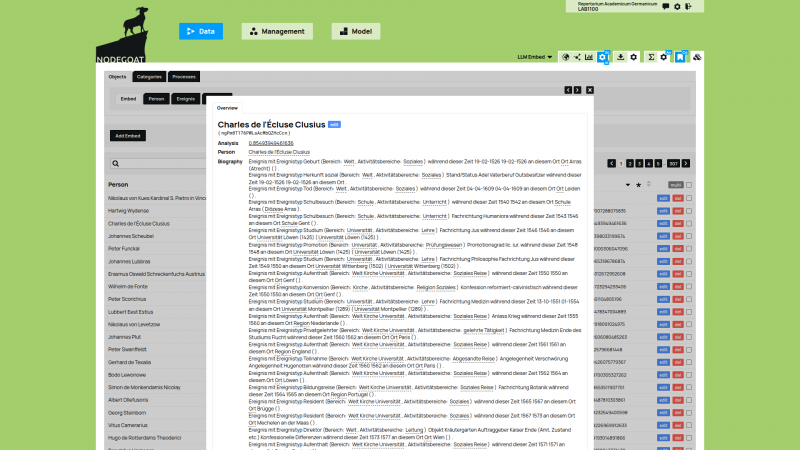
A database for historical data needs to be able to account for vague and uncertain data. A recently published series of blog posts describes how to create such a database in nodegoat.
LAB1100 collaborated with historian Tobias Winnerling of the Heinrich-Heine-Universität Düsseldorf to gather a variety of use cases in which uncertainty plays a role in historical databases.
The first blog post deals with incomplete source material, the second blog post deals with conflicting information, the third blog post deals with ambiguous identities.
Read the blog post 'How to store uncertain data in nodegoat' to learn more about these strategies and to learn how ontologies deal with various kinds of uncertain data.