Extended collaboration with the University of Bern
CORE Admin
LAB1100 has extended its collaboration with the University of Bern in 2020 with two new projects.
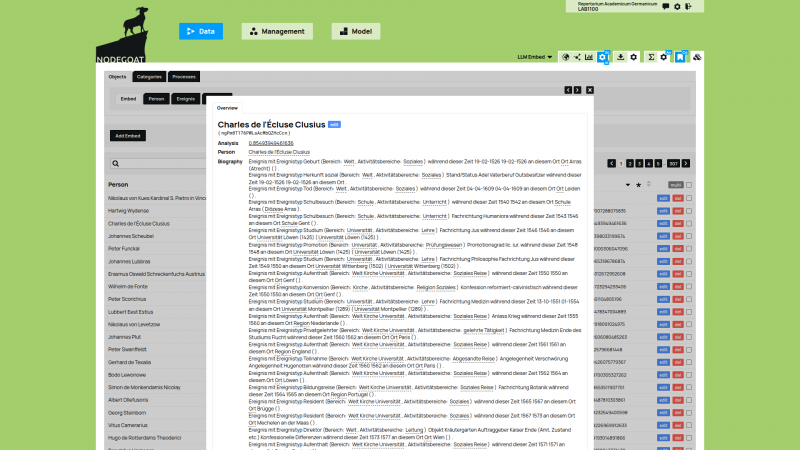
The Department of Medieval History of the University of Bern started its first project with LAB1100 in 2017 when they migrated their database of medieval scholars to a nodegoat installation. This project, the Repertorium Academicum Germanicum, has since used nodegoat as their primary data storage application and research environment. nodegoat is also used to create and publish diachronic geographical and social visualisations.
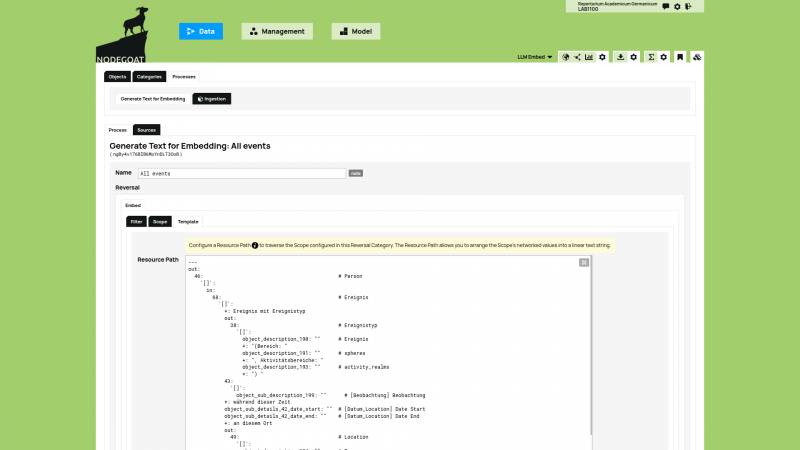
From the beginning of this year to 2021, LAB1100 participates in the SNSF SPARK project 'Dynamic Data Ingestion (DDI): Server-side data harmonization in historical research. A centralized approach to networking and providing interoperable research data to answer specific scientific questions', led by Kaspar Gubler, head of Digital Development at the Repertorium Academicum Germanicum.
A third collaboration started in March of this year when the Faculty of Humanities of the University of Bern set up a nodegoat Go service for its researchers and students. A set of new tutorials has been created to serve this user base by Kaspar Gubler.