Data as DNA
CORE Admin
LAB1100 is exploring new approaches to the discovery of patterns in historical texts.
LAB1100 is setting up a new project that aims to apply pattern recognition techniques developed in the field of bioinformatics to transcribed handwritten documents. This project will develop a tool that is able to produce a data-driven index of terms based on any type of textual data. As the tool will rely on reoccurring patterns, and not on semantics, the application will be language-agnostic and will be able to deal with spelling variations and transcription errors.
LAB1100 aims to rely on algorithms that have been developed in the field of bioinformatics for the discovery of DNA sequences.
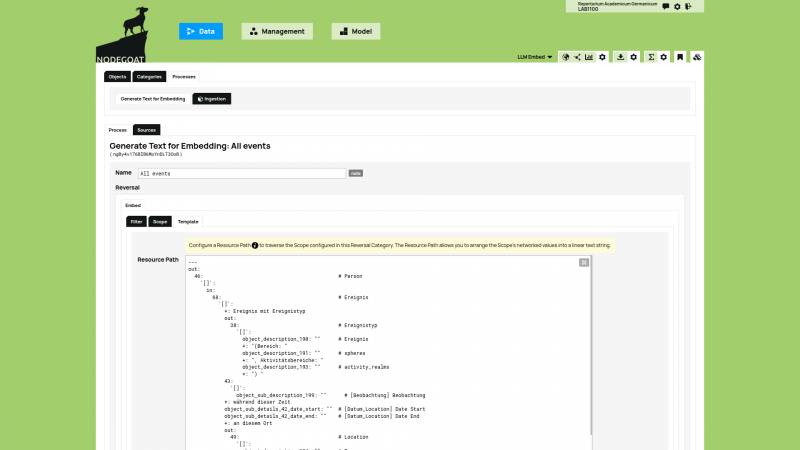
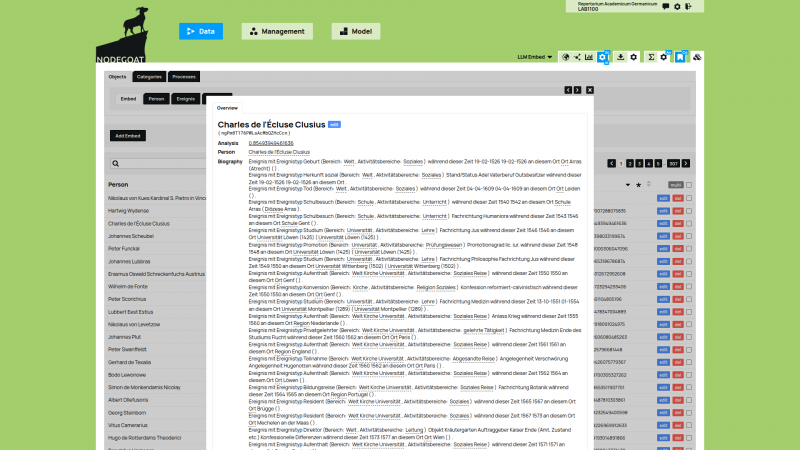
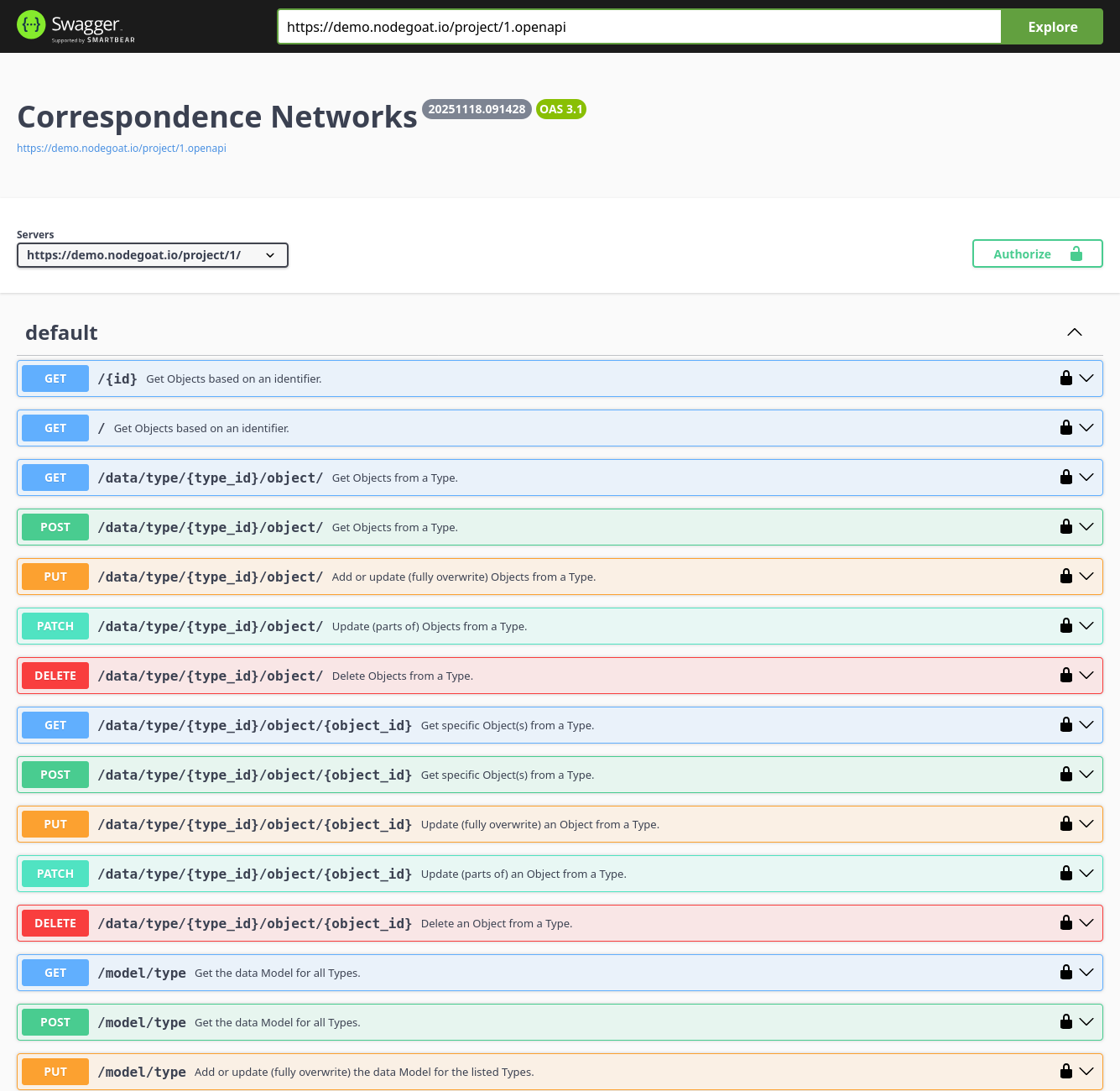
The purpose of this project is not to provide scholars with a tool that shows 'the most relevant' terms, but to create a heuristic tool that helps to identify terms and to locate the texts and pages in which these terms have been used. The tool can also be used to find texts or pages with co-occurring patterns. The tool's API and user interactions will be facilitated by a nodegoat research environment that will ingest the indices, weights, and references to the pages and texts.