New nodegoat Data Publication Module
CORE Admin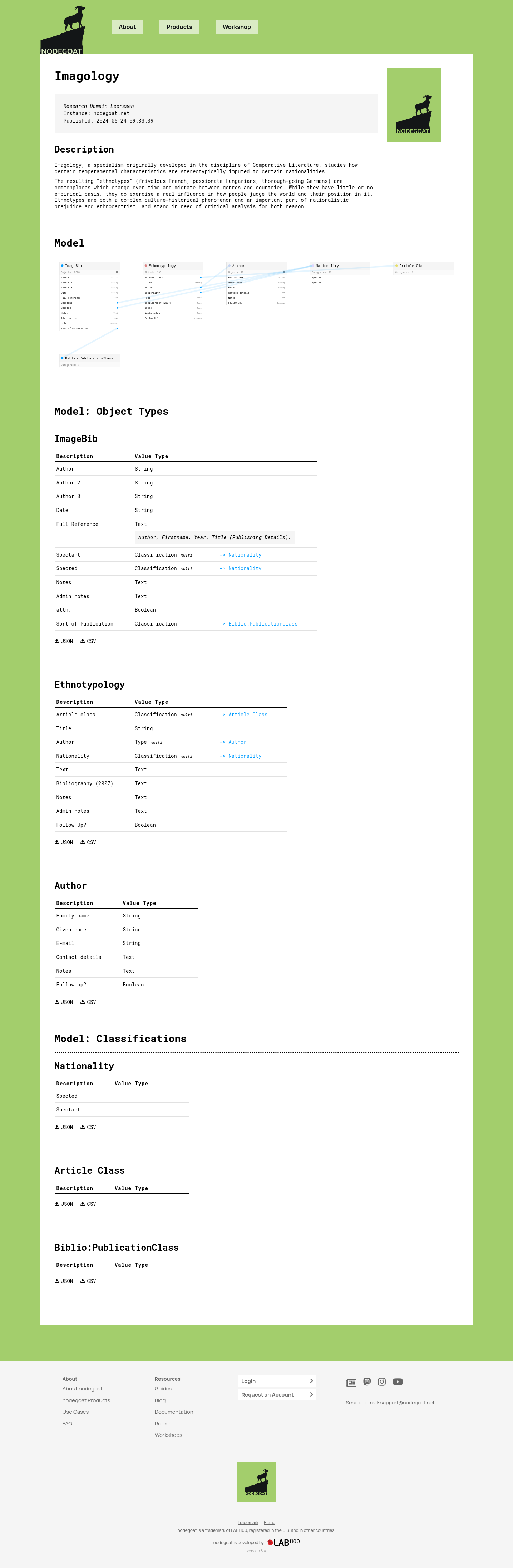
Publish your project with the new data publication module. nodegoat users can now select any project to generate a data publication that is web-accessible and downloadable as a ZIP-file. By generating a new publication a Project's data model and all of its data are published and archived. The publication remains accessible also when new publications are generated at a later stage.
Publications are stand-alone self-containing archives which include both the HTML-interface to the data model as well as all of its data in both JSON and CSV.
This new publish feature extends the existing data extraction and data publication options, i.e.: the export functionality, the API, and the public user interface.
All these functionalities ensure that nodegoat users are able to maintain a clear separation between their data and software as their data can always be extracted from the software. By means of this new nodegoat publication module it is possible to upload or update a data publication in a repository like zenodo.org by simply uploading a newly generated zip-file of your nodegoat project.
This module has become possible thanks to a commission of Joep Leerssen’s 2008 NWO Spinoza Prize fund.