Publication of dataset created in nodegoat by the MapModern project
CORE Admin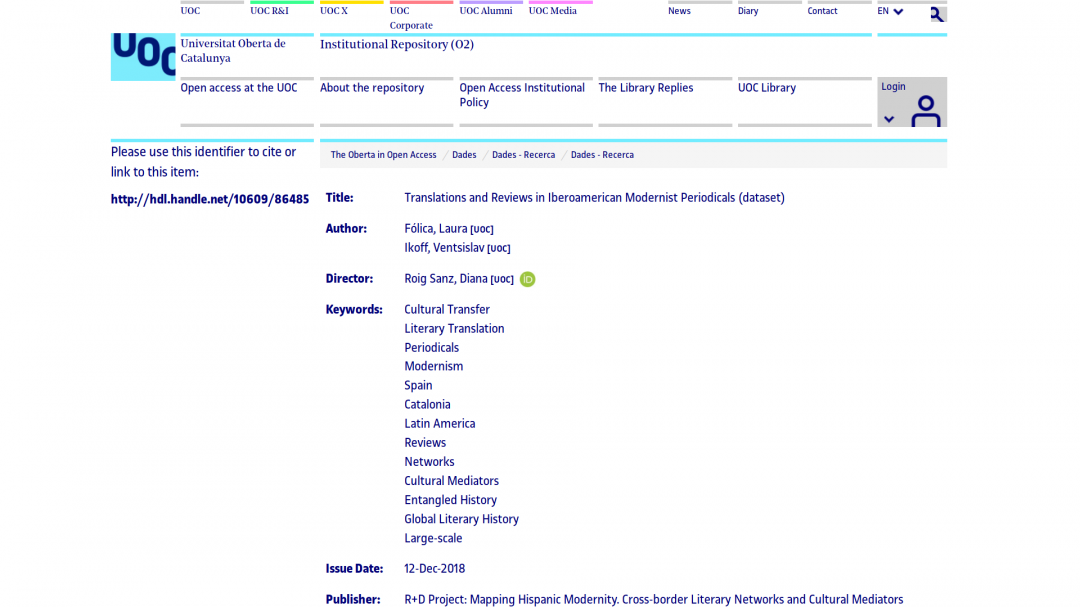
The MapModern project at the Universitat Oberta de Catalunya (UOC) that uses nodegoat to analyse cross-border literary networks and cultural mediators in the hispanic world between 1908 and 1939, has recently published a dataset on translations and reviews in hispanic modernist journals.
This dataset has been created in their nodegoat database by Laura Fólica and Ventsislav Ikoff, under the leadership of Diana Roig Sanz. With the help of the staff of the UOC library, the dataset has been made Dublin Core compliant. The dataset can be downloaded from the data repository of the UOC: http://hdl.handle.net/10609/86485, or from the EUDAT Collaborative Data Infrastructure which has assigned the dataset with a DOI: 10.23728/b2share.eb5c468d3dc3401c8b2fb4605d868a00.