LAB1100 celebrates its 10 year anniversary
CORE Admin
This year we celebrate our 10 year anniversary as LAB1100. We are grateful for all the exciting projects that we have been involved in, and for being able to collaborate with so many inspiring people. We look forward to continuing to work together with scholars from all over the world to deliver trailblazing research software.
LAB1100 was established as a company in March 2012. Our first tweet happened even a couple of months before that, while we (Pim van Bree & Geert Kessels) were finishing our studies (Media Studies and History, respectively).
We started to work on our first diachronic geographic visualisation of correspondence networks in October 2011, commissioned by Joep Leerssen in the framework of his Study Platform on Interlocking Nationalisms. The interactive visualisation that we launched in January 2012 still runs, and is described in "SpinTime: Dynamically Visualizing. How Diffusion Patterns Evolve over Space and Time".
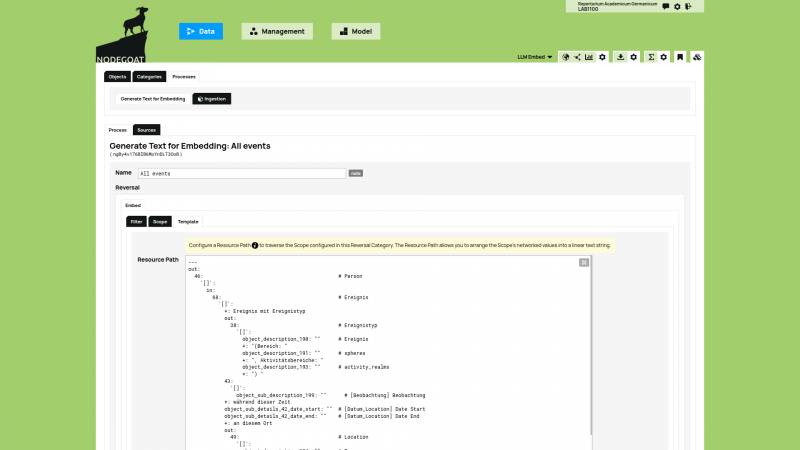
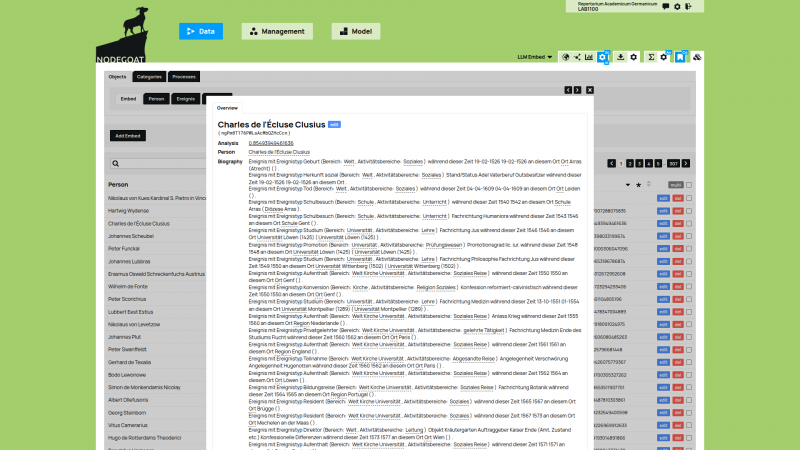
Later in 2012 we started the development of a web-based application to host the data of the initial diachronic geographic visualisation. We gave this application the name ‘Chrono Spatial Research Platform’ (CSRP). In 2013 we extended CSRP to become a research environment for the humanities and we renamed the application to ‘nodegoat’.
In 2013 we also gave our first presentations on CSRP/nodegoat in Jasna (SK), Hamburg (DE), Saint Petersburg (RU), and Luxembourg (LU). In 2014 we started to provide nodegoat services to Huygens ING (Mapping Notes & Nodes), Universiteit Gent and Universiteit Maastricht (TIC), Universiteit Leiden (Mapping Visions of Rome), and Arsip Nasional Republik Indonesia (Diplomatic Letters).
Since 2014 LAB1100 has been providing nodegoat services to Universiteit Utrecht, Universitat Oberta de Catalunya, ADVN | archief voor nationale bewegingen, GRIMMWELT, Université du Luxembourg, Universität Bern, Colorado College, University of Western Australia, Ludwig-Maximilians-Universität München, Universidade NOVA de Lisboa, Università degli Studi di Padova, NIOD Instituut voor Oorlogs-, Holocaust- en Genocidestudies, Znanstvenoraziskovalni center Slovenske akademije znanosti in umetnosti, Freie Universität Berlin, Norsk institutt for kulturminneforskning, The Australian National University, University of New Hampshire, Università degli Studi di Trieste, Universität Basel, Johann Wolfgang Goethe-Universität Frankfurt am Main, Forschungsstelle für die Geschichte der Hanse und des Ostseeraums, Universität Wien, Bölcsészettudományi Kutatóközpont, Uniwersytet Warszawski, Universiteit Antwerpen, Università degli Studi di Firenze, Centre national de la recherche scientifique, Wesleyan University, Joods Cultureel Kwartier, Leibniz Institut für Zeitgeschichte, Uppsala Universitet.
Click here to explore an interactive visualisation of our work in the past 10 years.