Data and Dialogue: Retrieval-Augmented Generation in nodegoat
CORE AdminWe have extended nodegoat in order to be able to communicate with large language models (LLMs). Conceptually this allows users of nodegoat to prompt their structured data. Technically this means nodegoat users are able to create vector embeddings for their objects and use these embeddings to perform retrieval-augmented generation (RAG) processes in nodegoat.
This development connects three of nodegoat’s main functionalities into a dynamic workflow: Linked Data Resources, the new vector store (nodegoat documentation: Object Descriptions, see ‘vector’), and Filtering. The steps to take are as follows:
Vector Embedding
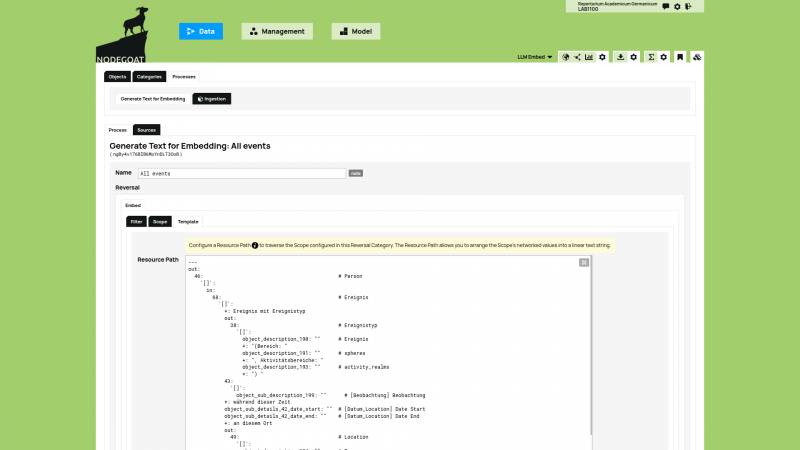
The first step is to use one or multiple Reversed Collection templates to determine the textual content for each Object. This step transforms any dataset stored as structured data into a textual representation that can be used as input value for the generation of a vector embedding. This allows the user to select only those elements that are relevant for the process.
 |  |
Next, the textual representation of each Object is sent to an LLM in order to create an embedding for each Object. The communication between nodegoat and an LLM is achieved by making use of Linked Data Resources and Ingestion Processes.
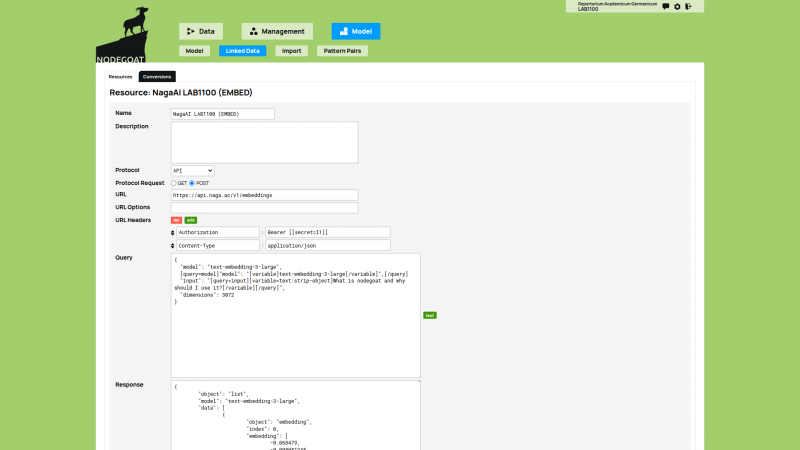 | 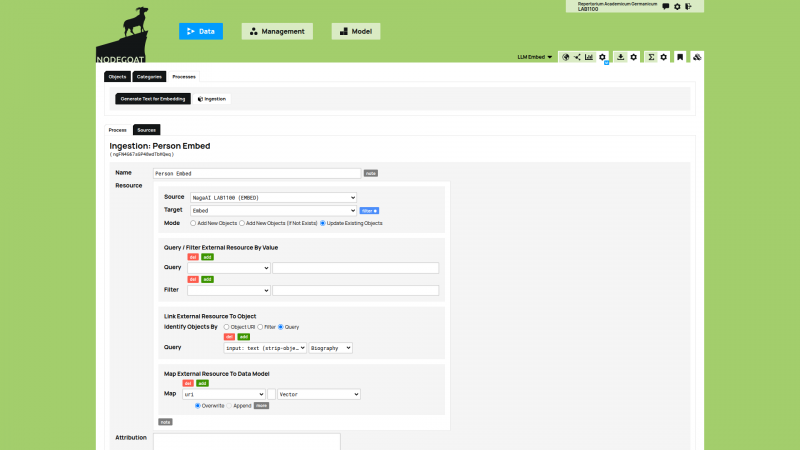 | 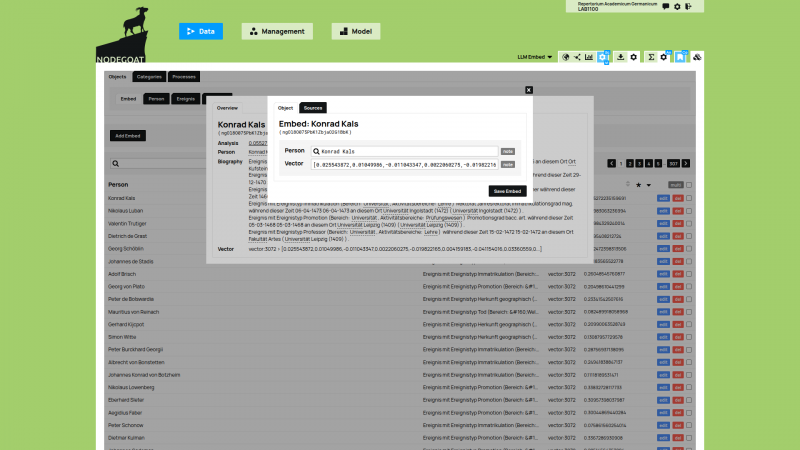 |
Linked Data Resources allow users to store a configuration to communicate with any existing endpoint that is accessible through API calls or SPARQL queries, and have been present and developed in nodegoat since 2015 nodegoat blog: Linked Data vs Curation Island. Ingestion Processes make use of Linked Data Resources and store the returned data to a mapped position in your nodegoat data Model. Linked Data Resources have been present in nodegoat since 2022 nodegoat blog: Connect your nodegoat environment to Wikidata, BnF, Transkribus, Zotero, and others. You can now use Linked Data Resources to connect to the APIs of LLMs (and vision-language models (VLMs), see nodegoat documentation: Linked Data Resource), or to LLM brokers (the example uses NagaAI). You then use Ingestion Processes to store the returned embeddings in your nodegoat environment. In order to store and use vector embeddings the value type ‘vector’ has been introduced.
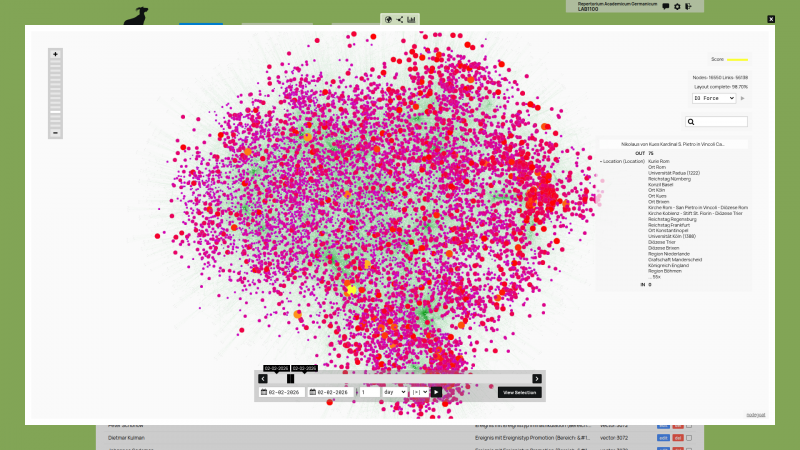
Retrieval-Augmented Generation
To perform retrieval-augmented generation processes in nodegoat a new module has been added that allows users to control the pipeline that will prompt their data. When a prompt is entered, a vector embedding is generated for this prompt based on the pre-configured Linked Data Resource. This vector embedding can be compared to the vector embeddings generated for all Objects to find the best matching vector embeddings to the vector embedding of the prompt. Finally, the collected text from the best matched Objects are sent to an LLM using another pre-configured Linked Data Resource that will be used to respond to the initial prompt.
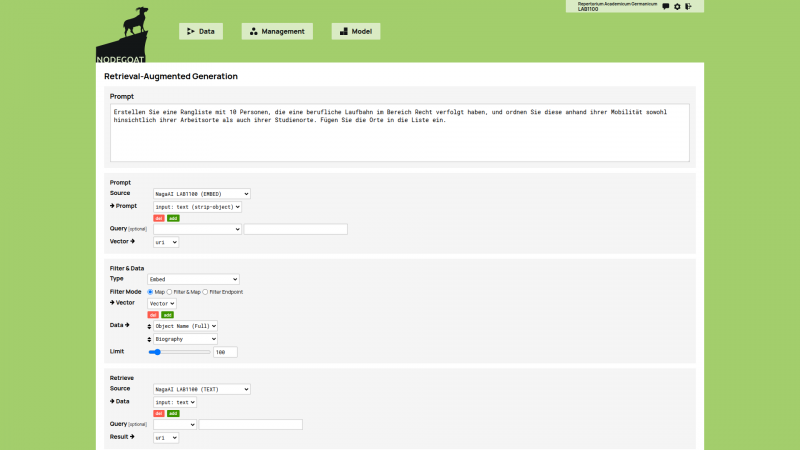 |  |
This approach combines the strength of high quality structured data with the new possibilities offered by LLMs. Thanks to the full control over the Object’s content and their context through Reversed Collections sent to the LLM, scholars can fully customise the data selection used for specific queries. This flexibility also allows users to switch between multiple embeddings for different Object Reversed Collections.
By using the proofed ‘hard data’ from a dataset in nodegoat, the chance of hallucinations by AI are greatly reduced. Still, it is important to note that while RAG is helpful to ask specific content related questions, the prompt has to be specific to ‘identifiable’ content. This means that the prompt has to relate to a sub-selection of a dataset and not be generic to the overall dataset. General questions or insights would require offloading the whole dataset or training a custom model and are therefore not suitable for this method.
The initial development phase of the nodegoat Retrieval module was commissioned by the project Repertorium Academicum (REPAC) of Universität Bern, and was first presented titled Artificial Intelligence and the Study of University Knowledge Spaces in the Holy Roman Empire (1250–1550) at the XIV Atelier Héloïse, 13-14 November 2025, organised by the Institute of History of the Czech Academy of Sciences, the Institute of Philosophy of the Czech Academy of Sciences, and Atelier Héloïse.